Stephen Roddy

![]()
![]()
![]()
![]()
![]()
![]()
Publications & Academic Outputs
Practice-based Research Outputs
Music Releases & Discography
Overview of Key Projects
Media Reviews
Pure Profile
Linktree
Bluesky
Home
A Musical Cyberenetics for the AI/ML Age.
Overview
This line of research began as part of my postdoctoral research exploring Automated Music Synthesis at the Department of Electrical and Electronic Engineering at Trinity College Dublin and since has been developed into a full research programme at the Department of Digital Humanities & Radical Humanities Laboratory at University College Cork. The original project (EE @ TCD) investigated methods for integrating machine learning and deep learning techniques (ML/DL) into the electronic music production and performance pipelines. In its current form (DH & RHL @ UCC) this research line has adopted Cybernetics as a framework for addressing the ethical, social and cultural factors at play in the design and application of AI/ML systems in music composition and performance.
Generative Machine Learning for Music Production Pipelines
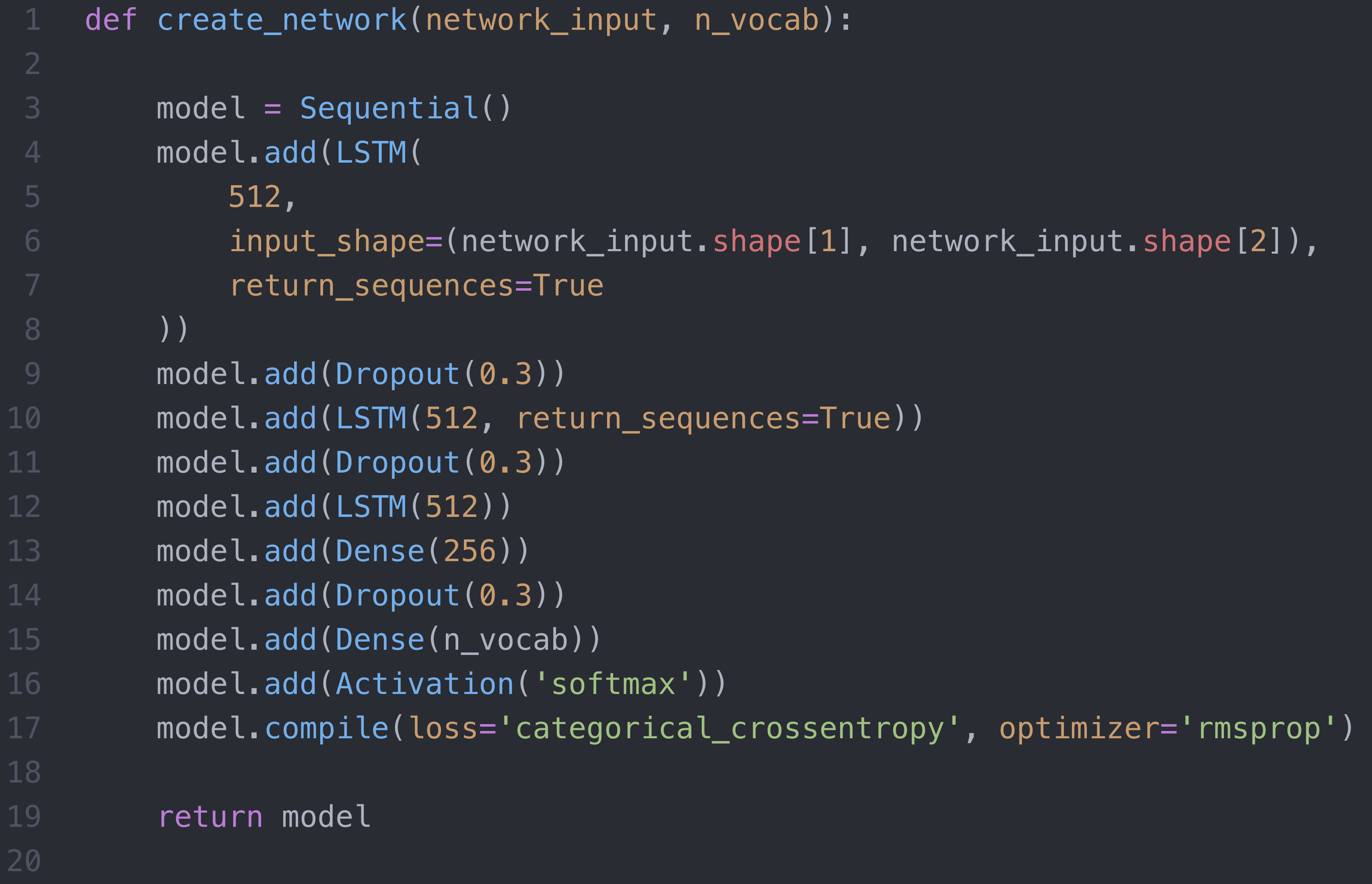
LSTM Architectures
Initial work focused on music production applications, specifically music generation at the MIDI event level. The models used Long short-term memory (LSTM) type architectures (using recurrent neural networks or RNNs) implemented with Tensorflow (Keras in Python). This allowed for the generation of new musical materials using features learned from an input MIDI data set. A variety of models were created in this way, some focusing on specific instruments and others focusing on specific artists, styles, and applications. The models developed for melody and harmony are generally focused on patterns at the note and chord levels.
Data set
To assemble the training data for initial experiments, I acquired a large number of MIDI files from a range of online sources across a wide range of musical styles. These experiments explored several musical genres/styles. The MIDI files were cleaned and split into sub-files on the basis of instrumentation etc. They were then mapped to integer values (with MIT’s Music21 toolkit) so that a one-hot encoding scheme could be applied.
Training
For training, data is split into n-length musical sequences. Each sequence is then paired with its following sequence element: n+1. This conditions the network to predict the next element for a given n-length sequence provided to it at prediction/generation time.
Results
While the models were effective, the musical outputs were, unsurprisingly, heavily tied to and constrained by the training data. Instances of direct replication and interpolation were obvious, though I addressed issues of overfitting with dropout layers. Extrapolation over musical materials tended to progress in a predictable manner. While a testament to the power of the techniques involved, this approach alone isn’t a sufficient method for generating interesting musical materials. More interesting outputs can be obtained by varying the input data set, the model architecture, and the hyperparameters of the model. These approaches can then be integrated into a larger music production pipeline to create interesting music. You can hear examples of this approach below. Relevant models created during this phase were the KennyG_ENERATOR and DefLSTM.
Musical Outputs: 30 Epoch Opus
30 Epoch Opus, is a short EP of AI-driven music. It features 4 musical works in diverse styles. The harmonic materials (melodies and harmonies) for each piece were composed using deep learning models both of which had an LSTM-based architecture.
The models were trained on MIDI renderings of the tracks from Def Leppard’s 1987 classic Hysteria. However, I couldn’t find a good version of the song Excitable so I used Photograph instead. Although that track appears on the 1984 album Pyromania, it shares a similar aesthetic to the tracks on Hysteria. The models were specifically trained on the guitar and bass lines with singing and drum information removed.
The instruments and timbres that have been chosen to synthesize (or sound out) these materials were provided by the composer rather than either of the models. Instead, 4 distinct approaches to texture and timbre were employed, 3 of which involve the manipulation of samples to some degree while the fourth approach involved modal synthesis. The result is 4 pieces with markedly different sonic palettes spanning electronic, noise, and pseudo-contemporary styles.
To create interesting harmonic/melodic results, the model used for the first 3 tracks is left partially underfit and uses highly novel input data chosen for its originality. This underfitting allows some features present in the original data to “shine through” but prevents the material from becoming an overly generalised representation of the inputs. This leaves space for an element of chance and surprise in the output. The model architecture and hyperparameters have been selected to support this approach. The model used for the fourth track, 100 Epoch Opus, is a much better fit for its training data. The originality of the harmonic materials here stems from a process of trial and error where a large number of outputs were auditioned before the novel material presented itself.
This work along with Signal to Noise Loops, and other topics in the application of Artificial Intelligence to music, were discussed in detail during a June 2022 interview for Gwaith Sŵn’s Sonic Darts on Resonance FM. You can listen back to the interview here:
Further Steps
This initial work was followed with the development of a GAN-based system but the long training times involved made this approach less useful than the LSTM systems for generating musical materials as part of a traditional music production workflow. The LSTM systems described above were easily integrated with Python notebooks allowing for better control and interaction when running in cloud computing environments during a standard music production workflow. I also explored the application of MusicVAE, which originated with Google’s Magenta Project, which proved tricky to re-train on-the-fly during the production workflow. Regardless, I did make use of both of these approaches in other projects along with itrations on the LSTM-based techniques described above. For example, an updated version of the the model used in 30 Epoch Opus titled, 2Def2Lep was used in the production of Whispering Signals, and Loopscape #1 on the Signal to Noise Loops compilation and GAN-based models were used to create live visual materials for the Indices on the Body project.
Whispering Signals
The musical loops on this track were generated using 3Def3Lep an LSTM-based machine learning model trained on a similar corpus of materials to those explored on 30 Epoch Opus: MIDI renderings of the tracks from Def Leppard’s 1987 classic Hysteria. For some reason, the model produces excellent musical information for experimental and ambient compositions.
In this iteration of the model, additional musical parameters were captured from the original dataset and the result was mapped to looping musical structures.
The sounds here involve a mixture of purely digital sound synthesis using a variety of techniques, processed samples, and re-synthesized samples. The final composition is quiet and delicate.
Loopscape #1
Layers of atmospheric drones loop over one another in this richly detailed tour through a cybernetic soundscape. Waves of noise swell and crash over the sonic landscape revealing the delicate musical lamentations suspended just below the surface. A sense of awe and longing permeates the piece making for an other-worldly listening experience.
This piece was created with signal, noise, and generative AI methods in mind once again. There are no sonification methods this time around. After experimenting with the MusicVAE model to produce some lackluster, materials I reverted back to my own 3Def3Lep model to produce musical information that better suits the style of the project and my own personal taste. Materials produced by the model were mapped to sound using a variety of sound synthesis routines in Reaktor. These materials were then heavily processed using techniques similar to my earlier collections of works Stardust Sonata and the other pieces here that experiment with timbre and texture: 61years and Soma. This time, however, the harmonic information across the frequency spectra of both channels (which I was thinking of as the signal coming through from the original generative model) was split from the noise information.
The noise information was then processed using the ‘extensive structures’ methodology I developed on earlier works. I then composed these elements to create the finished piece. The result is a kind of journey through a meditative soundscape composed of loops of signal and noise that sometimes interlock and evolve together and at other points fall into contrast with one another. It represents a return to an exploration of signals and noise, on both the timbral and texture levels with structures derived from a generative AI model.
CV & ML Techniques for Gestural Interaction in Live Music Performance & Installation
The second phase of the project explored computer vision (CV) and ML techniques for gestural control of performance systems (UAVs: drones, and music/sound synthesis). My colleagues and I at the Department of Electrical and Electronic Engineering TCD, designed and built a gestural control interface that could be used to control the flight of a drone. The hardware required to communicate with the drone was designed and built by a colleague. I built the system gestural interface system HTML, Javascript, and Node.js and used the tone.js, p5.js, ml5.js libraries. This interface was integrated with a hardware setup in which an Arduino was used to control the RC device for the drone. The system allowed users to control the flight path of a drone through their hand movements. The users’ hand movements are captured via camera/webcam and analysed using the ml5js Posenet implementation. The system was installed and opened to the public during Trinity College Dublin’s 2019 Open Day. Alternative iterations of this concept were also created, in which the users’ hand movements were also sonified, converting the user interactions into musical sounds (w/ p5.sound.js & tone.js) and mapped to control the animation of the drone on a computer screen. While controlling the flight path of a drone through physical gestures feels novel and provides some entertainment value, it is the application of CV & ML techniques to the control of sound synthesis parameters, with on-screen visual feedback that proved most fruitful in this project.

Examples of these musical applications, built with ml5.js and p5.js are included below. Both prototypes require access to your webcam feed. To activate the prototypes first, click your mouse on the screen inside the animation area. Then, stand in front of your webcam and move your hands to control sonic and visual parameters. Make sure that your webcam can see both of your hands:
Stochastic Processes, Probabilistic Techniques, and Cybernetic Control Loops
During the production of 30 Epoch Opus, I found that noisier outputs tended to be more musically interesting. As such, I adapted the model architecture, ultimately creating the 2Def2Lep model, to take advantage of these noisier patterns. I explored this further across 3 tracks on the Darkness Visible EP. Here I dispensed with the ML approaches and instead designed a generative music system that produces musical materials using stochastic processes and probabilistic techniques. After its original initialization, system parameters are controlled by a series of self-regulating feedback loops. My aim here was to rethink the concept of “artificial intelligence” by moving beyond the “machine learning” hype and grift that has become ubiquitous at the time and instead finding the “intelligence” in techniques inspired by classical generative, algorithmic and stochastic music compositions. While the design of the system was informed by the works of Xenakis, Cage, Eno, and Cope, the final sonic result was engineered to adhere to my own aesthetic interestes and as such was a substantial stylistic departure from these works. The Darkness Visible EP was well received:
An experimental composer from Ireland, Stephen Roddy proves equally adept at crushing soundscapes as he does mysterious melodies. - Bandcamp New & Notable Mar 13, 2022.
unsettlingly beautiful ambient landscape with moving pads, arcing sounds of processed guitar and electronics and uneasy drones and percussive patterns. - Tome to the Weather Machine
Distorted synths sketch the sonic landscape while a steady beat, high energy drones and simple electronic arpeggios serve as a path through this fraught world where a sense of menace hover all around - Queen City Sounds and Art
You can learn more about the creation of the EP as well as the artwork design from the liner notes on Bandcamp.
opening to the ambient light at The Wrong Biennale

An audiovisual expression of “opening to the ambient light”, which uses a Javascript implementation of the Fast Fourier Transform to map musical data to visual information, was produced for the Becoming-Human pavillion curated by Isil Ezgi Celik of CapitArt for the 2023 edition of the Wrong Biennale. The piece will go on display in the Artsect Gallery in London at the start of November 2023 and be available online in the Virtual Exhibition until February 2024.
Information about the exhibition can be accessed on the websites of The Wrong Biennale and CapitArt website here:
For an overview of the ethos and operation of The Wrong Biennale see the follwoing article by Fakewhale’s FW<LOG>. It includes an interview with David Quiles Guilló, the founder of the Wrong Biennale and features my audiovisual composition “opening to the ambient light”.
Overview of the piece
opening to the ambient light is a stochastic composition expressed in an ambient style through generative means. It is informed in its structural realization by Xenakis’ stochastic work while its aesthetic aspect is realized in reference to Milton’s Paradise Lost. Gordon Pask’s cybernetic conversation theory provided a conceptual apparatus to approach Deleuze’s becoming-machine, that mode of existence in which the border between the human and machinic becomes less a force of division and more of a method of integration through deterritorialization. Sonically the piece conjures something of the interplay of light and darkness that continually recurs across Milton’s epic poem Paradise Lost. This is recontextualized in terms of man and machine as generative audiovisual techniques render the struggle between chaos and cosmos as randomly generated parameters that become intelligible compositional choices thanks to a series of self-correcting feedback loops at the micro, meso, and macro levels of the stochastically driven generative music system underlying the piece. The sonic and visual result is a conversation in which the light and dark become immanent for the listener through their dialog with one another. Man and machine cease to be at odds here and rather a third thing, Deleuze’s becoming-machine is set in process. This process in turn announces itself both visually and sonically As the fixed identity of the human as composer/artist and machine as tool is challenged in this piece as the machine makes compositional choices from within a possibility space defined in collaboration with the human, but not entirely by the human. The fixed identity of the composer and the visual artist are disregarded here as a process of transformation, disrupts established musical and visual categories opening up a space for new creative possibilities. In this way, the conversation itself between sound & space, light & dark machine & human, operating as becoming-machine, thus producing the work
Ethical, Social and Politcal Dimensions of AI/ML
Alongside the technical and creative and posibilities opened up by AI/ML technologies, this research line has also explored the ethical, social and political dimensions of AI adoption in the creative arts. I have explored these questions during my time with the IEEE Committee on Ethically Aligned Design for Artists. Our first publication, The Voice of the ARtist in the age of the Algorithm explores some of the ethical questions raised by the application of AI/ML technologies in the creative industries and mkaes recomendations:
- Artists should mobilize and collectively exert power to encourage and influence the development of human artist-centric AI systems.
- The IP generated by artists should be respected by AI systems (for both commercial and non-commercial purposes).
- AI systems in the creative arts should utilize human-centric principles and sustainable design whether commercially or non-commercially oriented.
You can read our paper in greater detail here:
Developing a Cybernetics of AI/ML
Following on from my work with the committee I began the development of a cybernetics approach to the application of AI/ML technologies in the creative arts. The point of this approach is to account for the the master-servant dynamic at play in AI/ML applications as well as the anxiety that advancing AI/ML systems will replace human creatives. The approach developed instead is informed by creative applications of cybernetics, and the work of George E. Lewis, in particular. You can read more about this approach here:
An example of how this approach can be applied in practice is provided by my Signal to Noise Loops project which you can read more about here:
This research line has been increasingly concerned with how artists navigate the myriad pitfalls and pathways that AI/ML technologies open up for their sonic arts practices. It has focused specifically on the re-apropriation of ML technologies away from the increasingly politicised narratives surrounding “AI”.
- Roddy, S. & Parmar, R. (2023). AI/ML in the Sonic Arts - Pitfalls and Pathways. Resonance: The Journal of Sound and Culture, 4(4).
- Roddy, S. (2023). Nao Tokui in Conversation with Stephen Roddy (Interview). Resonance: The Journal of Sound and Culture, 4(4).
This framework has been further developed with reference to the recent rethinking of cybernetics for the AI/ML era in the work of Yuk Hui and N. Katherine Hayles as well as the early cybernetic music of Roland Kayn, Jaap Vink and others as explored in presentations for the Intangible Modalities and UbiMus24 symposia:
This line of thought is crystallised with reference to the phenomenon of “AI Slop” in the Artificial Media volume for Springer’s Cultural Computing series:
Tags
Cybernetics. Artificial Intelligence. Machine Learning. Computer Vision. Musical Interaction. Gestural Interfaces. Creative Coding. Web Applications. Generative Music. Stochastic Processes. Probabilistic Techniques.
Hosted on GitHub Pages — Theme by orderedlist
Page template forked from evanca